
AI से अपनी आवाज़ क्लोन करना – Theo Von के साथ क्या हुआ?
AI से अपनी आवाज़ क्लोन करना (या कम से कम कोशिश करना) मैं अपने वीडियो के लिए Theo Von जैसी आवाज़ वाले AI वॉयस का इस्तेमाल करता था। यह मज़ेदार था — इसमें थोड़ी पर्सनैलिटी आ जाती थी, और सच कहूं तो मेरी खुद की इंग्लिश प्रोनन्सिएशन से कहीं बेहतर लगता था।
लेकिन आज, जब मैं नया वीडियो बनाने बैठा, तो पता चला कि वह आवाज़ — मेरी कीमती Theo Von — अब Play.ht पर उपलब्ध नहीं है।
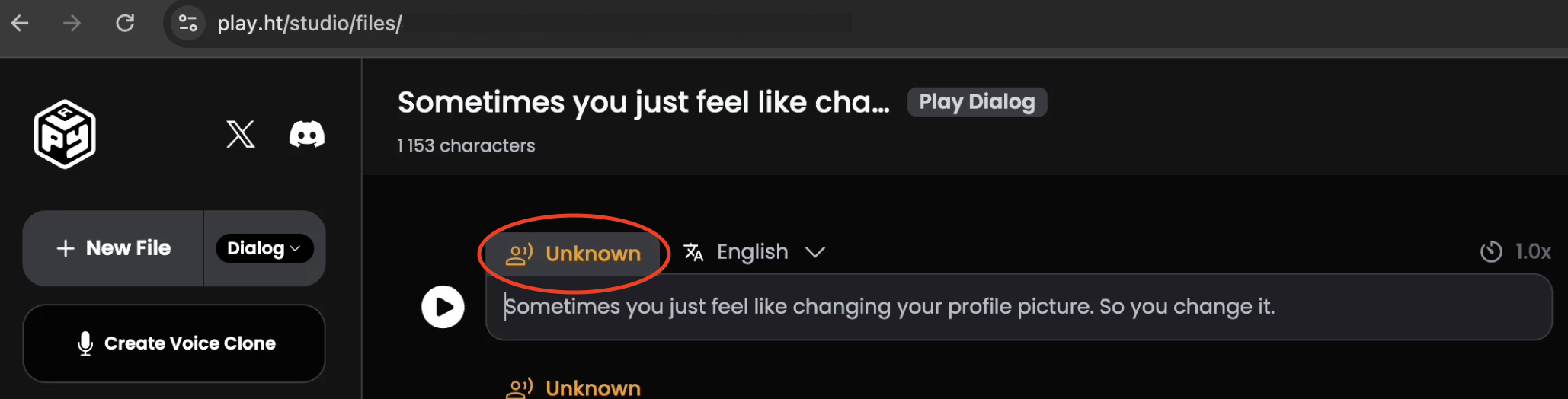
मैंने साइट खोली, अपने पुराने वीडियो स्क्रिप्ट में से एक खोला, और जिस वॉयस का मैंने पहले इस्तेमाल किया था, उसका नाम भी नहीं था। बस... खाली। मैंने मैन्युअली ढूंढने की कोशिश की — वॉयस लिस्ट में देखा। "Theo Von" टाइप किया — कुछ नहीं मिला। "Chris" भी ट्राय किया, जो पहले Theo जैसी आवाज़ का नाम था। फिर भी कुछ नहीं।
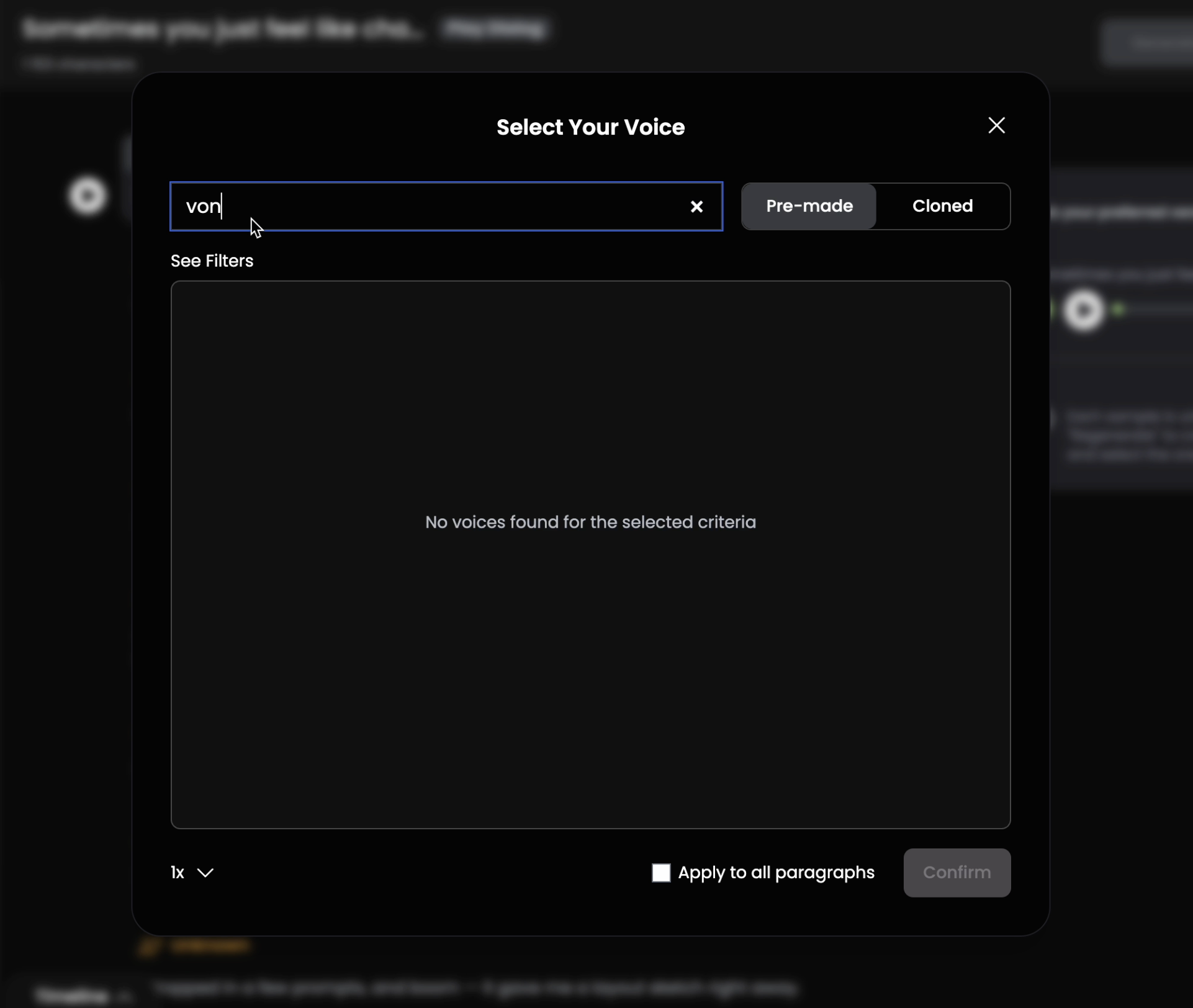
बस, अब चैनल डिलीट करने का टाइम आ गया है। शायद Theo Von को पता चल गया और वह नाराज़ हो गया कि मैं उसकी AI कॉपी यूज़ कर रहा हूँ।
अब क्या?
तो, स्वाभाविक रूप से, मैंने Mr. Robot — ChatGPT — की मदद ली।
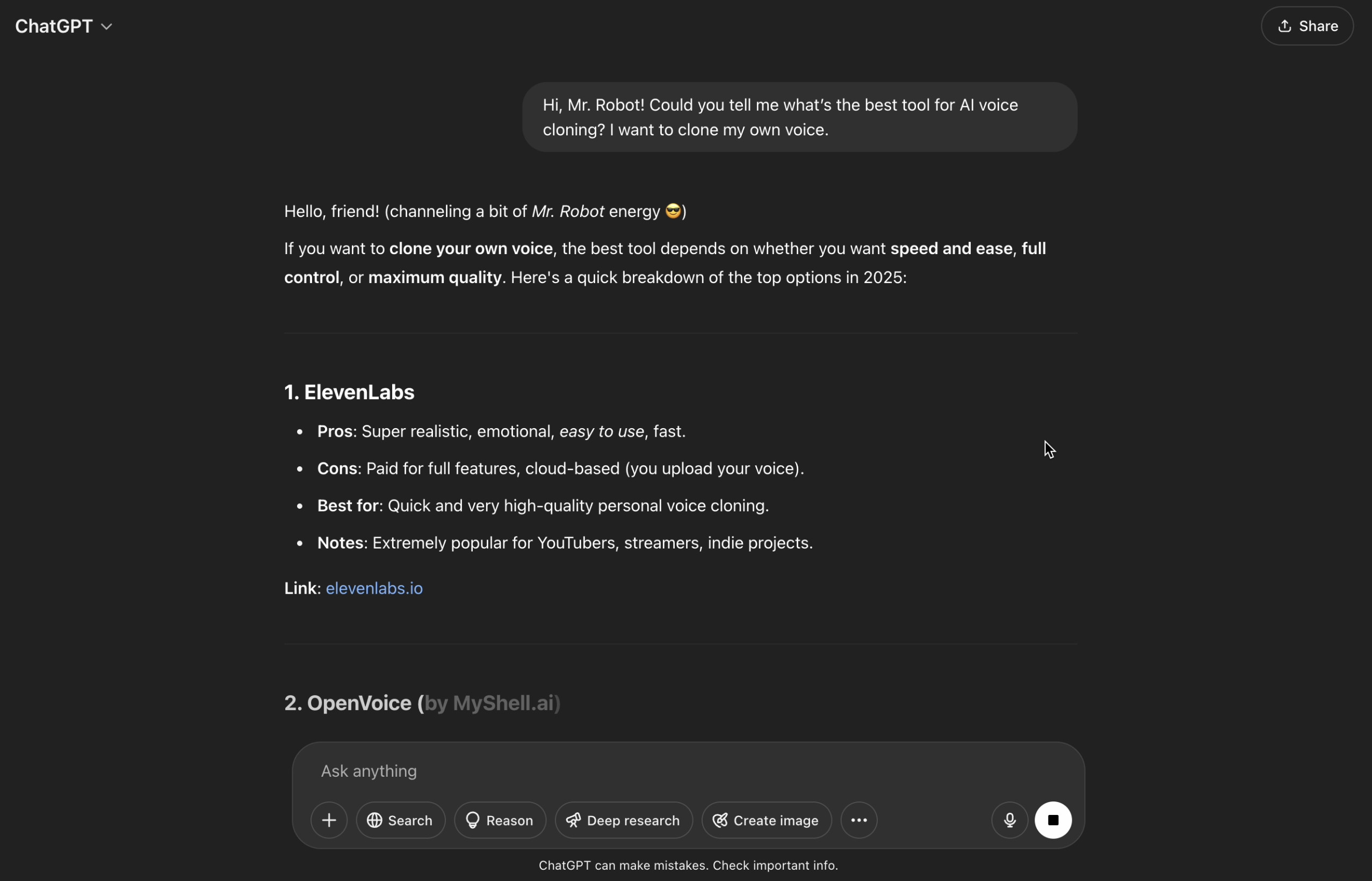
उसने ये सजेशन दिए:
पहला: ElevenLabs। बहुत अच्छा है। लेकिन पेड है। तो... छोड़ो।
दूसरा: OpenVoice। फ्री लगता है। बस, यही चाहिए था। ट्राय करते हैं।
मैं काफी समय से खुद अपनी आवाज़ में कंटेंट बोलना चाहता था। लेकिन मेरी इंग्लिश उतनी अच्छी नहीं है, और मुझे नहीं पता लोग मुझे 10 मिनट तक सुनना चाहेंगे या नहीं। तो अपनी आवाज़ क्लोन करने का आइडिया — लेकिन AI से उसे बेहतर बनवाना — परफेक्ट लगा।
मैंने OpenVoice का डिस्क्रिप्शन जल्दी से पढ़ा और जादुई शब्द देखे: मल्टीलिंगुअल वॉयस क्लोनिंग। बस, यही चाहिए था।
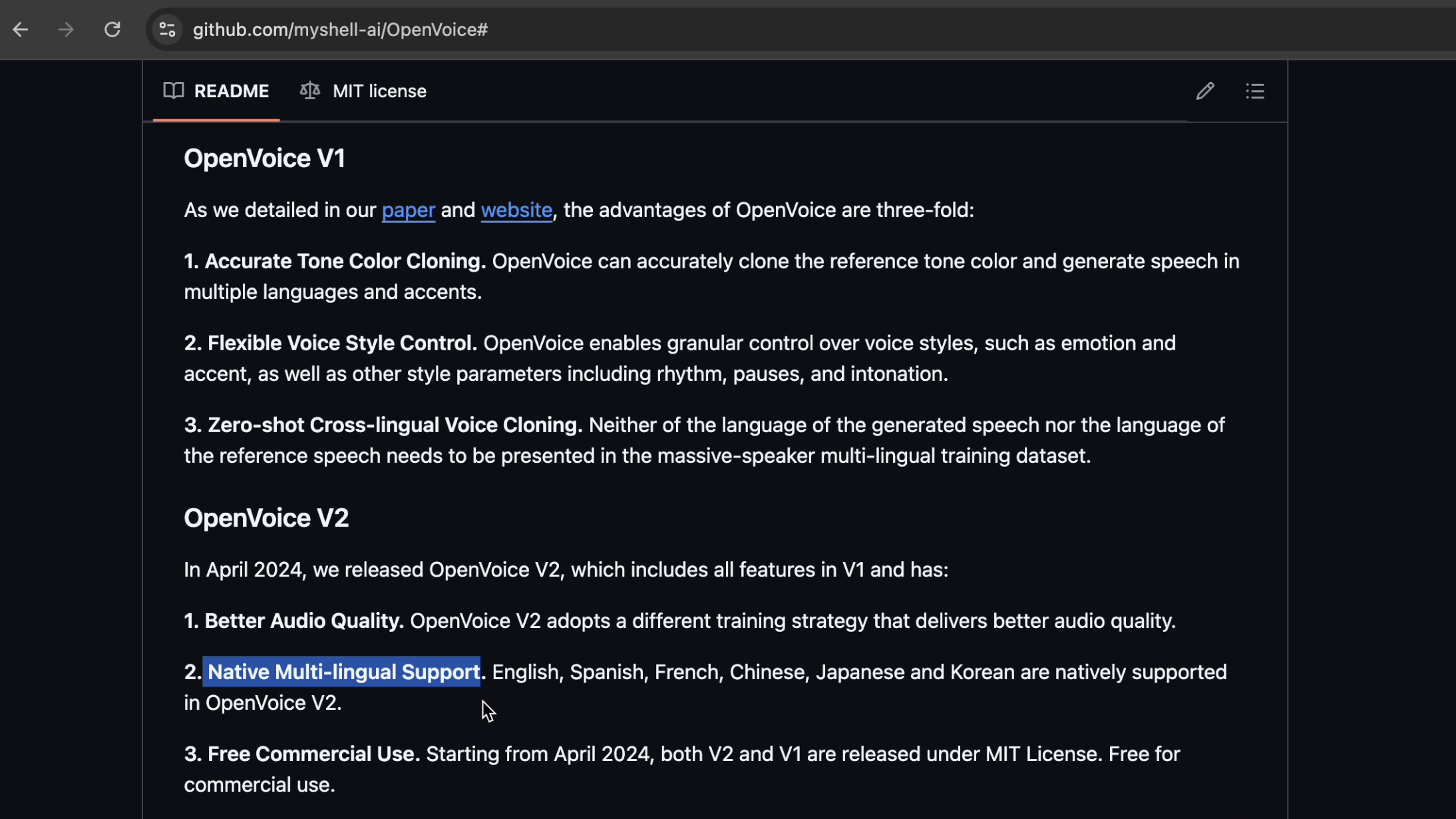
तो मैंने रिपॉजिटरी क्लोन की और notebooks/demo_part1.ipynb खोला।
पहला सेल... बूम। प्रॉब्लम। मॉडल गायब हैं। कोई चेकपॉइंट्स नहीं। क्लासिक।
लेकिन कोई बात नहीं — थोड़ा गूगल किया, सही फाइलें मिल गईं, डाल दीं, सब रीस्टार्ट किया और फिर से चलाया।
इस बार, लगता है काम कर गया।
मैंने एक छोटा सा वॉयस सैंपल रिकॉर्ड किया, नोटबुक फिर से चलाया... और आखिरकार अपना AI-जेनरेटेड ऑडियो मिल गया।
सुनते हैं।
निराशा। मेरी असली आवाज़ की जगह एक बहुत ही सामान्य TTS वॉयस मिली, शायद मेरी टोन की थोड़ी झलक... लेकिन मेरी पर्सनैलिटी बिल्कुल नहीं।
अगला स्टेप होता — खुद का मॉडल ट्रेन करना — जो सिर्फ एक छोटा सैंपल देने से कहीं ज्यादा जटिल है।
नहीं... रहने दो।
तो मैंने बस कोई दूसरा रेडीमेड वॉयस चुन लिया। अगर आपको ये दिलचस्प लगा — या आपके पास कोई बेहतर उपाय है — तो कमेंट करें। पढ़ने के लिए धन्यवाद।
अगला पढ़ें
- 12 फ़रवरी 2026

AI के युग में वेबसाइट का पुनः डिज़ाइन और पारंपरिक SEO का अंत
मेरी वेबसाइट के पुनः डिज़ाइन की कहानी, GSAP एनीमेशन और क्यों AI के युग में डिज़ाइन अब खोज से ट्रैफ़िक नहीं लाता।
- 9 जनवरी 2026

ट्रैफ़िक रिपोर्ट: दिसंबर 2025 – जनवरी 2026
पिछले 30 दिनों में वेबसाइट ट्रैफ़िक — एक संक्षिप्त रिपोर्ट और अवलोकन।

